Atomic Data
- published-by: Ontola
- related: JSON-AD
- creators: @joep-meindertsma
Thoughts
- like Solid, requies the use of a personal server, aka Personal Online Datastore.
- requiring resolvable properties and emphasizing resolvable URLs seems limiting.
- not being able to use common namespace:terms is kinda sad. you could adopt a no-modification- (or -restriction?-) -of-existing classes and properties
- giving up "anyone can say anything about anyone" is too much.
- i.e., "Atomic only allows those who control a resource's subject URL endpoint to edit the data. This means that you can't add triples about something that you don't control."
- requiring online-ness and lookups for parsing is too troubling.
- it is true that minting IRIs is troublesome.
Comparisons
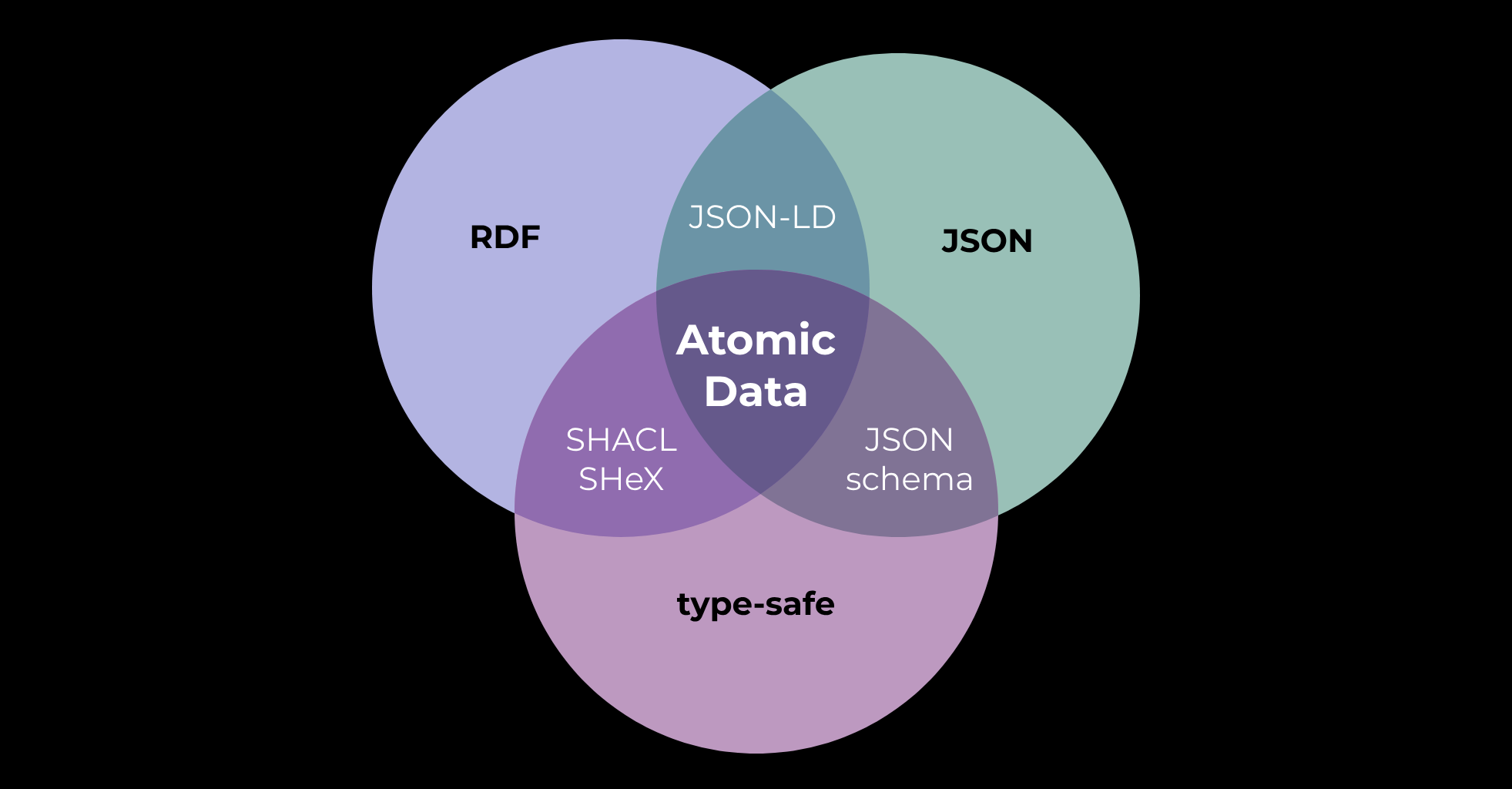
vs RDF
(from https://docs.atomicdata.dev/interoperability/rdf)
- Atomic calls the three parts of a Triple
subject,propertyandvalue, instead ofsubject,predicate,object. - Atomic does not support having multiple statements with the same
<subject> <predicate>, every combination must be unique. - Atomic does not have
literals,named nodesandblank nodes- these are allvalues, but with different datatypes. - Atomic uses
nested Resourcesandpathsinstead ofblank nodes - Atomic requires URL (not URI) values in its
subjectsandproperties(predicates), which means that they should be resolvable. Properties must resolve to anAtomic Property, which describes its datatype. - Atomic only allows those who control a resource's
subjectURL endpoint to edit the data. This means that you can't add triples about something that you don't control. - Atomic has no separate
datatypefield, but it requires thatProperties(the resources that are shown when you follow apredicatevalue) specify a datatype. However, it is allowed to serialize the datatype explicitly, of course. - Atomic has no separate
languagefield. - Atomic has a native Event (state changes) model (Atomic Commits), which enables communication of state changes
- Atomic has a native Schema model (Atomic Schema), which helps developers to know what data types they can expect (string, integer, link, array)
- Atomic does not support Named Graphs. These should not be needed, because all statements should be retrievable by fetching the Subject of a resource. However, it is allowed to include other resources in a response.
vs Solid
similar goals to Atomic Data:
- Decentralize the web
- Make things more interoperable
- Give people more control over their data
Technically, both are also similar:
- Usage of personal servers, or PODs (Personal Online Datastores). Both Atomic Data and Solid aim to provide users with a highly personal server where all sorts of data can be stored.
- Usage of linked data. All Atomic Data is valid RDF, which means that all Atomic Data is compatible with Solid. However, the other way around is more difficult. In other words, if you choose to use Atomic Data, you can always put it in your Solid Pod.
But there are some important differences, too, which will be explained in more detail below.
- Atomic Data uses a strict built-in schema to ensure type safety
- Atomic Data standardizes state changes (which also provides version control / history, audit trails)
- Atomic Data is more easily serializable to other formats (like JSON)
- Atomic Data has different models for authentication, authorization and hierarchies
- Atomic Data does not depend on existing semantic web specifications
- Atomic Data is a smaller and younger project, and as of now a one-man show
Atomic Data is more easily serializable to other formats (like JSON)
Atomic Data is designed with the modern (web)developer in mind. One of the things that developers expect, is to be able to traverse (JSON) objects easily. Doing this with RDF is not easily possible, because doing this requires subject-predicate uniqueness. Atomic Data does not have this problem (properties must be unique), which means that traversing objects becomes easy.
Another problem that Atomic Data solves, is dealing with long URLs as property keys. Atomic Data uses shortnames to map properties to short, human-readable strings.
For more information about these differences, see the previous RDF chapter.
Authentication
Both Solid an Atomic Data use URLs to refer to individuals / users / Agents.
Solid's identity system is called WebID. There are multiple supported authentication protocols, the most common being WebID-OIDC.
Atomic Data's authentication model is more similar to how SSH works. Atomic Data identities (Agents) are a combination of HTTP based, and cryptography (public / private key) based. In Atomic, all actions (from GET requests to Commits) are signed using the private key of the Agent. This makes Atomic Data a bit more unconventional, but also makes its auth mechanism very decentralized and lightweight.
Solid advantages
- No inbox or notifications yet (issue) (Linked Data Notifications)
- No OIDC support yet. (issue)
- No support from a big community, a well-funded business or the inventor of the world wide web.
Shortnames
- Requiring Properties to resolve is part of what enables the type system of Atomic Schema - they provide the shortname and datatype.
Advantages of Shortnames
Readability: Shortnames can make your transactions and queries more concise and easier to understand, especially when dealing with complex Property names. Brevity: They reduce data size in transaction payloads. Potential Namespace Management: Shortnames can play a role in how you manage namespaces within your data model.
Important Considerations
- Name Collisions: Atomic Data guarantees uniqueness of the Subject-Property combination, mitigating shortname collisions within the context of an entity. However, if resources from multiple Classes with the same shortname are mixed, clients need a strategy to resolve potential clashes (see the Atomic Data FAQ you linked earlier).
- Not a Replacement for Full URIs: Shortnames are a convenience mechanism. Internally, Atomic Data still relies on full Property URIs.
- each Property URL must resolve to an online Atomic Data Property.
References
Backlinks