Formal Ontologies and Information Systems
- https://www.researchgate.net/publication/272169039_Formal_Ontologies_and_Information_Systems
- author: @nicola-guarino
Highlights
- In some cases, the term “ontology” is just a fancy name denoting the result of familiar activities like conceptual analysis and domain modelling, carried out by means of standard methodologies. In many cases, however, so-called ontologies present their own methodlogical and architectural peculiarities. On the methodological side, the main peculiarity is the adoption of a highly interdisciplinary approach, where philosophy and linguistics play a fundamental role in analyzing the structure of a given reality at a high level of generality and in formulating a clear and rigorous vocabulary. On the architectural side, the most interesting aspect is the centrality of the role that an ontology can play in an information system, leading to the perspective of ontology-driven information systems.
- In the philosophical sense, we may refer to an ontology as a particular system of catgories accounting for a certain vision of the world. As such, this system does not depend on a particular language: Aristotle’s ontology is always the same, independently of the laguage used to describe it. On the other hand, in its most prevalent use in AI, an ontology refers to an engineering artifact, constituted by a specific vocabulary used to describe a certain reality, plus a set of explicit assumptions regarding the intended meaning of the vcabulary words. This set of assumptions has usually the form of a first-order logical thory5, where vocabulary words appear as unary or binary predicate names, respectively called concepts and relations. In the simplest case, an ontology describes a hierarchy of concepts related by subsumption relationships; in more sophisticated cases, suitable axioms are added in order to express other relationships between concepts and to constrain their intended interpretation. The two readings of “ontology” described above are indeed related each other, but in order to solve the terminological impasse we need to choose one of them, inventing a new name for the other: we shall adopt the AI reading, using the word Conceptualization to refer to the philosophical reading.
- While ordinary relations are defined on a certain dmain, conceptual relations are defined on a domain space. We shall define a domain space as a structure <D, W>, where D is a domain and W is a set of maximal states of affairs of such domain (also called possible worlds).
- Consider now the structure <D, R> introduced in [17]. Since it refers to a particular world (or state of affairs), we shall call it a world structure. It is easy to see that a concetualization contains many of such world structures, one for each world: they shall be called the intended world structures according to such conceptualization.
- In general, there will be no way to reconstruct the ontological commitment of a laguage from a set of its intended models, since a model does not necessarily reflect a paticular world: in fact, since the relevant relations considered may not be enough to copletely characterize a state of affairs, a model may actually describe a situation common to many states of affairs. This means that it is impossible to reconstruct the correspondence between worlds and extensional relations established by the underlying conceptualization. A set of intended models is therefore only a weak characterization of a conceptualization: it just excludes some absurd interpretations, without really describing the “meaning” of the vocabulary.
- Since every model now carries the information concerning the state of the world it refers to, the undelying conceptualization can be reconstructed from the set of its intended models. In this case, if an ontology is axiomatized in such a way to have exactly the same models, then it would be a “perfect” ontology.
- Another possibility to increase the accuracy of an ontology consists of either adopting a modal logic, which allows one to express constraints across worlds, or just reifying worlds as ordinary objects of the domain.
- Of course, there is a tradeoff between a coarse and a fine-grained ontology committing to the same conceptualization:
- the latter gets closer to specifying the intended meaning of a vocabulary (and therefore may be used to establish consensus about sharing that vocabulary, or a knowledge base which uses that vocablary), but it may be hard to develop and to reason on, both because the number of axioms and the expressiveness of the language adopted.
- A coarse ontology, on the other hand, may consist of a minimal set of axioms written in a language of minimal expressivity, to support only a limited set of specific services, intended to be shared among users which already agree on the underlying conceptualization. We can distinguish therefore between detailed reference ontologies and coarse shareable ontologies, or maybe between off-line and oline ontologies: the former are only accessed from time to time for reference purposes, while the latter support core system’s functionalities.
- Domain ontologies and task ontologies describe, respectively, the vocabulary related to a generic domain (like medicine, or automobiles) or a generic task or activity (like dianosing or selling), by specializing the terms introduced in the top-level ontology
- Application ontologies describe concepts depending both on a particular domain and task, which are often specializations of both the related ontologies. These concepts oten correspond to roles played by domain entities while performing a certain activity, like replaceable unit or spare component.
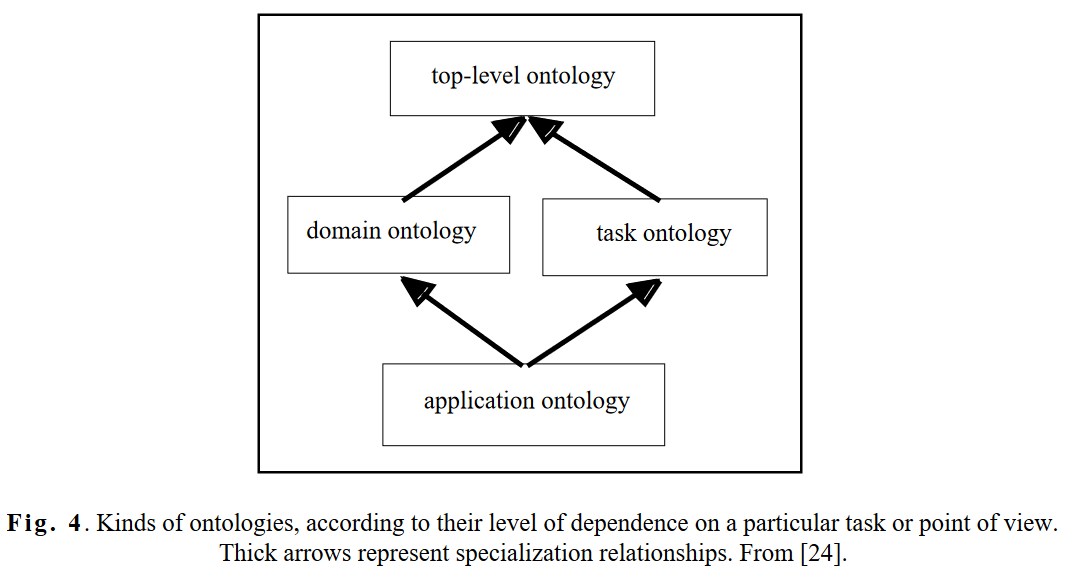
- As a final consideration, it may be important to make clear the difference between an application ontology and a knowledge base. The answer is related to the purpose of an otology, which is a particular knowledge base, describing facts assumed to be always true by a community of users, in virtue of the agreed-upon meaning of the vocabulary used. A generic knowledge base, instead, may also describe facts and assertions related to a paticular state of affairs or a particular epistemic state. Within a generic knowledge base, we can distinguish therefore two components: the ontology (containing state-independent iformation) and the “core” knowledge base (containing state-dependent information).
Ontology-driven Information Systems
- When discussing the impact an ontology can have on an IS, we can distinguish two orthogonal dimensions: a temporal dimension, concerning whether an ontology is used at development time or at run time (i.e., for an IS or within an IS)
Backlinks